The workings of simulating DOOM
9 april, 2019

Rick Vink
“Neural networks are a lot of fun to play with. The range of possibility are immense, because of the ability to both process and generate audio, video, control inputs and many other kind of data types into your model.”
Neural networks are a lot of fun to play with. The range of possibility are immense, because of the ability to both process and generate audio, video, control inputs and many other kind of data types into your model. Many people on Youtube share their own creative take on what is possible with neural networks. In this blog I share my creative take on neural networks. It’s a simulation of a smaller level with one enemy of the game DOOM in which you can go left, right and shoot. In the end it was able to predict the next frame based on a few previous frames and the controller input. Thereby, I created my own simulation of the game doom.
Model Architecture
The pipeline of predicting the next frame frame consists of three separate neural networks: encoder, LSTM and decoder. The encoder compresses a frame of the size of 128 by 256 pixels to a smaller package of just 32 float values. This compressed representation of the frame is combined with the keyboard/joystick input and together with 4 other frame + input states fed into an LSTM network that predicts the next encoded representation of the next frame. Finally, this compressed layer is decoded to 128 by 256 pixel image again.
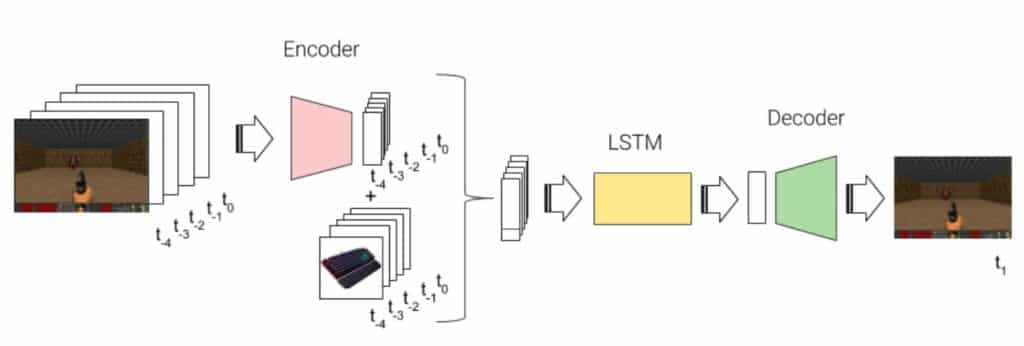
For the Nerds: The pipeline of predicting the next frame frame consists of three separate neural networks: encoder, LSTM and decoder. The encoder compresses a frame of the size of 128 by 256 pixels to a smaller package of just 32 float values. This compressed representation of the frame is combined with the keyboard/joystick input and together with 4 other frame + input states fed into an LSTM network that predicts the next encoded representation of the next frame. Finally, this compressed layer is decoded to 128 by 256 pixel image again.
Training
The training happened in two stages. In the first stage the encoder and decoder are combined into one network, forming a so called autoencoder. The job of the autoencoder is to learn how to compress the image and decompress it in such a way that the output matches the input as close as possible. This part of the training took about 8 hours in order to get a decent result. The input images were all chopped and grayscaled during the training in order to focus on the game play aspect.

The second part of the training is aimed on learning the order of frames. A LSTM was trained on the compressed frames of the game and the keyboard inputs at that point in time and tried to match the next compressed layer.
Results
The autoender was able to capture the essence of a frame really well. I hooked up a few sliders to the compressed dense layer of the neural network in order to change the scenery of the game. Thereby it was possible to draw or retract a gun at any point in the game and drag the walls from one side to another. Predicting the next frame during game play most definitely satisfied my expectations. It predicted the movement to the right and the left quite well and the game speed felt just right. It most definitely has quite a few glitches, but heck, what is a game without glitches!
Acknowledgements
This project is inspired by the work of a Youtube video “Does my AI have better dance moves than me?”. He is great and a lot of fun so check him out! Tensorflow is used to create the neural network model and VIZDoom is used to train the model.
Wil jij zelf Machine Learning technieken toepassen?
“Uitstekende cursus om mee te beginnen. Het werd goed uitgelegd, een fijn tempo en een goede verhouding tussen zelf dingen kunnen doen en de uitleg.”
Ger van Leusen – Chemisch Analist bij Vitens