Onderzoek zelf de Corona uitbraak
7 april, 2020

Masoed Shakori
“Informatie voorzieningen moeten gebruiksvriendelijk zijn, maar nog belangrijker met dit soort gevoelige informatie is de betrouwbaarheid. “
Het nieuws staat iedere dag opnieuw in het teken van de meest recente corona cijfers. Maar wat betekenen deze getallen voor het verloop van de uitbraak? Er wordt gesproken over de effecten van de maatregelen, maar waaruit blijkt dit? In deze blog vertel ik over de beschikbare data, waar het vandaan komt en hoe je er zelf mee aan de slag kunt gaan. Zo kun je de uitbraak zelf onderzoeken en misschien wel meer inzichten creëren!

De wereldberoemde kaart
Misschien ken je de kaart hierboven al. Het is een visualisatie van het aantal bevestigde corona besmettingen over de hele wereld. Het geeft een overzicht van de verspreiding van het virus en hoe dit zich ontwikkelt. Neem hier een kijkje, als je dat nog niet gedaan hebt. Maar waar komt de kaart vandaan?
De kaart is 22 januari gepubliceerd door Johns Hopkins University CSSE (Center for Systems Science and Engineering). Het is ontwikkeld door professor Lauren Gardner en haar student Ensheng Dong en wordt onderhouden door verschillende organisaties. Hun doel was om onderzoekers, zorgverleners en de gewone burger een gebruiksvriendelijke manier te geven om de uitbraak de volgen. Dit vind ik goed gelukt!
Maar waar komt de data vandaan? Informatie voorzieningen moeten gebruiksvriendelijk zijn, maar nog belangrijker met dit soort gevoelige informatie is de betrouwbaarheid. Dat lijkt wel goed te zitten, want de kaart wordt dagelijks vernieuwd met de laatste data van o.a. de WHO, de CDC (VS), de ECDC (EU), de NHC (China) en meer! Achter deze data zit dus ongelofelijk veel werk van mensen en organisaties over de hele wereld. Johns Hopkins heeft voor ons gemak alle gegevens verzameld en online beschikbaar gesteld. Niet alleen in de vorm van de kaart, maar ook de ruwe data kan gedownload worden. De ruwe data bevat alle gegevens over het aantal besmettingen, overledenen en herstelde mensen. Daarnaast vind je er ook rapporten van de WHO. Hierna laat ik zien waar de data gepubliceerd is en wat er precies in staat.
De data
Johns Hopkins publiceert de verzamelde gegevens op Github, dit is een website die gebruik maakt van de versie beheer software Git. Het handige van versie beheer is dat alle dagelijkse updates bijgehouden worden. Zo kun je later goed zien welke data wanneer beschikbaar was. Verder stelt de website je in staat de data te downloaden en automatisch up-to-date te houden op je eigen PC.
Laten we naar de data kijken! De makkelijkste manier om de data in te zien is als volgt: Ga naar deze link, klik op de groene knop en kies: Download ZIP.

Nu de map op je PC staat kunnen we kijken wat er in zit. In de hoofdmap staan o.a. 3 mappen. archived_data is data met een oude format en kan genegeerd worden. De eerder genoemde WHO rapporten zijn te vinden in de map who_covid_19_situation_reports. Zie hieronder een voorbeeld.

Maar waar we echt naar op zoek zijn staat in de map csse_covid_19_data. Hier vinden we de mappen csse_covid_19_daily_reports en csse_covid_19_time_series. De eerste bevat één bestand per dag met de status per land. Maar de laatst genoemde map bevat één bestand met alle data per dataset: aantal bevestigde besmettingen, overledenen of herstelde mensen. In dat bestand staan de cijfers per dag voor alle landen. Dus het bestand time_series_covid19_confirmed_global.csv heeft rijen met landen en per land is het totaal aantal bevestigde besmettingen per dag te zien. Zo kun je bijvoorbeeld per land inzien hoe de verspreiding zich heeft ontwikkeld in de loop der tijd. Met Excel kun je de bestanden meteen openen en een kijkje te nemen. Hieronder laat ik zien hoe je de data kunt inzien en visualiseren met Python.
Zelf aan de slag
Ik gebruik Jupyter Notebook, maar als je niks wilt installeren kun je ook gebruik maken van Google Colab. Je hebt dan alleen een Google account nodig om op de website in te loggen. Hieronder staat het eerste stukje code. In de eerste regel importeer ik de pandas library. Dit stelt ons in staat een aantal handige functies te gebruiken, waaronder pd.read_csv() om data te laden. Voor dit voorbeeld zal ik bovengenoemde bestand time_series_covid19_confirmed_global.csv bekijken. Hieronder zie je hoe ik de data laad met behulp van de pandas library en vervolgens de eerste 5 rijen weergeef.
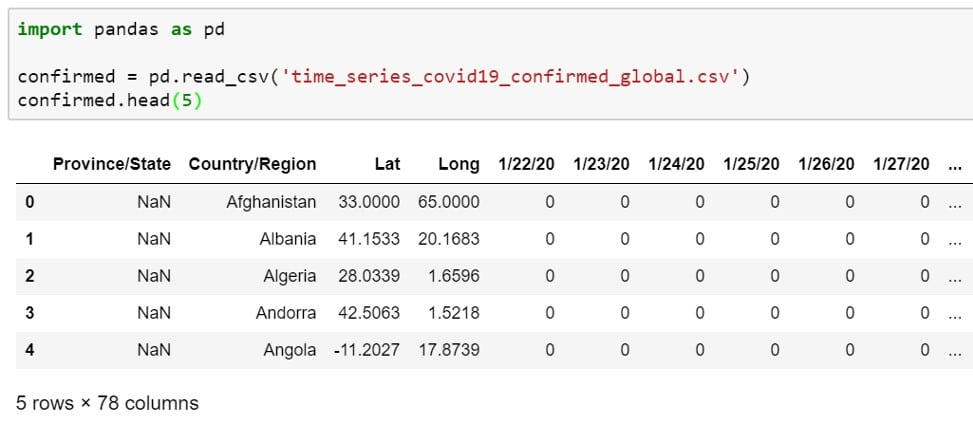
Het lijkt erop dat we de data op alfabetische volgorde van Country/Region (land/regio) hebben staan. In de eerste vier kolommen staat de locatie informatie. Vanaf de vijfde kolom staat de data die we zoeken: het totaal aantal bevestigde besmettingen per dag. We zien onder de tabel staan dat er 78 kolommen zijn, dus dat zijn 78 – 4 = 74 dagen aan data vanaf 22 januari 2020.
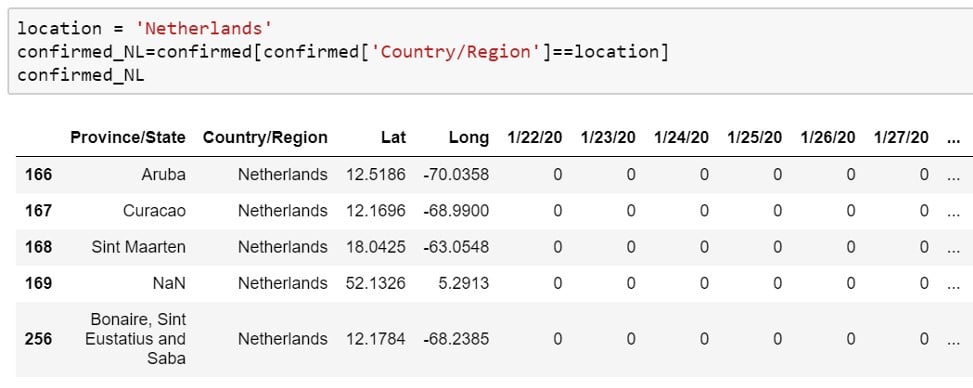
Laten we de data voor Nederland opzoeken. Ik definieer hieronder de variabele location = ‘Netherlands’. Ik gebruik die variabele in de volgende regel om te zoeken naar rijen die Netherlands hebben staan in de kolom Country/Region. Door een variabele te gebruiken, kun je later makkelijker zoeken naar een ander land. De gevonden rijen schrijf ik vervolgens toe aan confirmed_NL. In Jupyter Notebook kun je de inhoud van confirmed_NL zien door het los op te schrijven. In andere programma’s moet misschien de nette manier gebruikt worden: print(confirmed_NL). We zien dat er 5 rijen voldoen aan de zoekopdracht Country/Region == Netherlands.
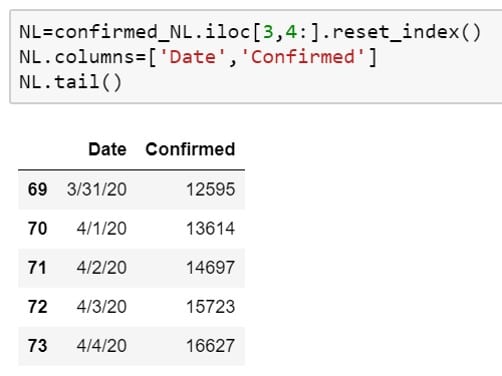
Wij zijn nu geïnteresseerd in het aantal besmettingen in de rij met index 169. Ik gebruik de functie iloc[] om de vierde rij en alle kolommen vanaf de vijfde kolom te selecteren (let op: Python telt vanaf 0). Het aantal besmettingen in rij 169 is nu een kolom geworden die ik de naam Confirmed geef. Daarna laat ik de laatste 5 rijen zien met de functie tail(). We zien dat we nu een mooie dataset hebben met het totaal aantal bevestigde besmettingen per dag. Door de laatste rijen te bekijken, zien we dat de data doorloopt tot en met 4 april 2020.
Nu is het heel eenvoudig om het aantal besmettingen te plotten. Ik importeer hiervoor de pyplot library en plot de kolom Confirmed. Verder benoem ik de assen en geef ik de data weer als puntjes.

Voilà, het verloop van het aantal bevestigde besmettingen in Nederland is te zien in een mooie grafiek! Je kunt de beschikbare data op verschillende manieren visualiseren, maar dit is één van de simpelste. Op dezelfde manier kun je ook de gegevens van andere landen zien en vergelijken. Je kunt ook andere libraries importeren om analyses en voorspellingen te doen. Denk bijvoorbeeld aan het volgende:
- Wat voor grafiek zou je door de bovenstaande data kunnen plotten om een voorspelling te doen?
- Kan een logaritmische schaal helpen met inzichten over de maatregelen?
- Hoe vergelijk je de uitbraak in verschillende landen met elkaar
- Welke kanttekeningen kun je maken aan de beschikbare datasets?
De Technische Universiteit Eindhoven beschrijft in een artikel hoe zij dezelfde data hebben gebruikt om voorspellingen te doen. Klik hier als je precies wilt zien hoe ze dit hebben gedaan.
Ik hoop dat deze blog je inzage heeft gegeven in hoe je zelf aan de slag kunt gaan met data. Je hoeft alleen maar data te vinden en de magische kracht van programmeren te gebruiken! Er is in deze blog niet ingegaan op de programmeertaal zelf. Wil je een beter begrip van bijvoorbeeld Python, data analyse of Machine Learning? Kijk dan bij onze cursussen!
Wil jij ook leren programmeren met Python?
“Je krijgt een goed beeld hoe de basis van Python werkt. Duidelijk stof en veel oefeningen inclusief een duidelijke handleiding. Goede cursus om de eerste stappen van het programmeren te leren.”
Michel Degger – Acceptatie verzekeringen