AI-pipelines versus AI-agents
26 juni, 2025

Farisch Hanoeman
Artificiële intelligentie is de laatste jaren uitgegroeid tot de motor onder talloze Nederlandse digitale diensten. Toch is de terminologie vaak verwarrend. In blogs lees je over pipelines die teksten vertalen en beelden classificeren, terwijl conferenties vol staan met sessies over agents die complete bedrijfsprocessen afhandelen. Het doel van dit artikel is helder: we leggen de twee concepten naast elkaar, tonen aan hoe ze zich in gebruik gedragen en bespreken de voordelen en uitdagingen. Door de voorbeelden en tips kun je straks bewust kiezen welke architectuur voor jouw organisatie het meest geschikt is.
De structuur is zo opgezet dat je kunt inzoomen op je eigen situatie. We beginnen met een definitie van beide termen, illustreren vervolgens het verschil met herkenbare voorbeelden, staan stil bij belangrijke overwegingen en ronden af met een duidelijke lijst van voordelen én uitdagingen. Elk onderdeel bevat concrete tips waardoor je sneller beslissingen neemt zonder lange theoretische omwegen.
Wat is het verschil tussen een AI-pipeline en een AI-agent?
Om het verschil te begrijpen, helpt het om eerst naar het algemene doel van elk concept te kijken. Een AI-pipeline is in de basis een opeenvolging van vaste stappen waar data doorheen stroomt. Denk aan het malen van graan in een molen: de korrels worden bovenin gestort, de stenen draaien, en onderaan komt meel tevoorschijn. Iedere stap heeft een vooraf gedefinieerde functie en er is weinig ruimte voor improvisatie. De pipeline past uitstekend bij taken die repeterend zijn en waarbij een voorspelbare respons noodzakelijk is.
Een AI-agent daarentegen werkt volgens een feedbacklus. De agent krijgt een opdracht, observeert de omgeving, plant zijn volgende stap, voert die uit en evalueert of hij dichter bij het doel is. Vervolgens herhaalt hij dat proces. Vergelijk het met een kok die een nieuw recept uitprobeert: hij proeft, voegt kruiden toe, zet het vuur hoger of lager en past het plan continu aan. De agent is dus dynamischer en kan zelfstandig middelen inzetten zoals zoekopdrachten, code-executie of API-calls om het doel te halen.
Het verschil komt vooral tot uiting in autonomie en flexibiliteit. Pipelines volgen een rechte lijn, agents bewegen door een landschap vol zijpaden. Pipelines leveren hetzelfde resultaat zolang de invoer binnen de grenzen blijft. Agents kunnen hun gedrag aanpassen wanneer de werkelijkheid afwijkt van het ideale scenario. Dat maakt ze krachtig, maar brengt ook extra complexiteit met zich mee. Het is als het kiezen tussen een spoorlijn en een terreinwagen: de trein is snel zolang er rails liggen, de terreinwagen komt overal maar vraagt meer onderhoud.
Praktijkvoorbeeld AI agent: digitale reisassistent
We bekijken een eenvoudig voorbeeld van een digitale reisassistent die werkt met behulp van Autogen. In dit systeem werken drie agenten samen in een groepsgesprek. Elke agent heeft een eigen taak en draagt bij aan het totaalplaatje.
- Reisagent: Deze agent staat in direct contact met de gebruiker. Hij beantwoordt vragen en verzamelt eerst de juiste informatie voordat hij een antwoord formuleert.
- Locatieonderzoeker: Deze assistent ondersteunt de reisagent door onderzoek te doen naar bestemmingen. Hij maakt gebruik van functie-aanroepen om via de SERP API gegevens op te halen van Google Maps. Denk aan informatie over bezienswaardigheden, restaurants, overnachtingsmogelijkheden en meer.
- Gebruikersvertegenwoordiger: Deze agent fungeert als tussenpersoon voor de gebruiker in het groepsgesprek. Hij zorgt ervoor dat de communicatie tussen de gebruiker en de andere agenten soepel verloopt.
Dankzij deze samenwerking kan de gebruiker eenvoudig vragen stellen en snel antwoorden krijgen, gebaseerd op actuele informatie. De agenten nemen elk een duidelijke rol op zich, waardoor het systeem efficiënt en overzichtelijk blijft.
Dieper in de AI-pipeline: vaste rails voor voorspelbare taken
Nu we het fundamentele onderscheid kennen, is het handig om in te zoomen op de pipeline zelf. Een pipeline bestaat meestal uit drie lagen. Ten eerste de pre-processing, waar ruwe data wordt opgeschoond, getokeniseerd of genormaliseerd. Vervolgens volgt de model-laag, die een of meerdere machine-learning-modellen inzet om voorspellingen of transformaties uit te voeren. Tot slot is er post-processing, waar de output wordt omgezet naar een voor de gebruiker bruikbaar formaat, bijvoorbeeld een JSON-object of een downloadbaar rapport.
Een belangrijk kenmerk van pipelines is dat zij een CI/CD toepassen. Iedere stap kan afzonderlijk worden getest en gemonitord. Daardoor kunnen teams nieuwe versies van een model veilig uitrollen zonder het volledige systeem te ontwrichten. Mocht er iets misgaan, dan wijst de foutmelding direct naar de betreffende stap. Verder zijn pipelines eenvoudig te schalen: je zet meer compute in op de drukste fase. Voor een ondertiteldienst betekent dat bijvoorbeeld een extra GPU-knooppunt voor de spraak-naar-tekst-module.
Ook qua governance heeft de pipeline een streepje voor. Doordat de volgorde vastligt, voldoet hij makkelijker aan eisen van auditors. Denk aan de Algemene Verordening Gegevensbescherming, waar transparantie over dataverwerking een vereiste is. Een pipeline logt voor elke stap de invoer en uitvoer, waardoor je achteraf kunt aantonen dat persoonsgegevens correct zijn verwerkt. Dit voordeel verklaart waarom banken, verzekeraars en zorginstellingen pipelines vaak als eerste keuze zien wanneer ze AI in productie brengen.
Praktijkvoorbeeld: AI agents en privacy instructies
Hieronder bespreken we een voorbeeld waarin een AI-agent niet goed omgaat met privacy-instructies van de gebruiker. Dit laat zien waarom duidelijke afspraken en controlemechanismen belangrijk zijn.
- Situatie: Een gebruiker vraagt een agent om te helpen bij een project waarbij gevoelige persoonlijke gegevens worden verwerkt. De gebruiker geeft duidelijk aan dat deze informatie niet gedeeld of opgeslagen mag worden in externe systemen.
- Wat gaat er mis: De agent begrijpt de privacybeperking niet goed, of herkent het belang ervan onvoldoende. Daardoor voegt hij per ongeluk de gevoelige gegevens toe aan een gedeeld document of een openbare database.
- Gevolgen: De gegevens komen terecht bij mensen die daar geen toegang toe zouden mogen hebben. Dit kan leiden tot schending van de privacy, juridische problemen, verlies van vertrouwen van de gebruiker en mogelijke schade voor de personen van wie de data is gelekt.
- Wat we hieruit leren: Het is belangrijk dat AI-systemen zorgvuldig omgaan met instructies over privacy. Ze moeten deze goed begrijpen en er strikt naar handelen. Daarnaast is het verstandig om regelmatig te controleren of de agent correct werkt. Zo kan de gebruiker tijdig ingrijpen en fouten herstellen voordat er echt iets misgaat.
Dit voorbeeld laat zien hoe belangrijk het is om privacygrenzen duidelijk te communiceren en te blijven controleren of de agent zich daaraan houdt.
Dieper in de AI-agent: een digitale collega die plannen maakt
Waar de pipeline fungeert als lopende band, doet de agent meer denken aan een slimme assistent. Hij kan meerdere tools in willekeurige volgorde gebruiken, afhankelijk van wat het moment vraagt. Neem een helpdesk-agent: die start met een introductiebericht, bekijkt de vraag van de klant, zoekt in een kennisbank, analyseert logbestanden, formuleert een antwoord en vraagt zo nodig door. Dat alles gebeurt zonder dat elke stap van tevoren volledig is gescript. Daardoor kan de agent inspelen op nuance, iets dat in een starre pipeline vaak ontbreekt.
Agents worden meestal gebouwd met frameworks zoals CrewAI, AutoGen of LangGraph. Deze bibliotheken bieden bouwstenen voor waarnemen, plannen, tool-aanroepen en geheugenbeheer. Een nieuw project begint vaak met een designdocument waar doelen, tool-definities en veiligheidsgaranties worden beschreven. Vervolgens testen ontwikkelaars de agent in een sandbox, waarbij zij loggen hoe hij beslissingen neemt. Na een aantal iteraties gaat de agent live en krijgt hij echte gebruikersdata te zien.
Een interessant detail is dat agents steeds vaker samenwerken. In een zogenoemde multi-agent-setup heeft elke agent een specialisme, bijvoorbeeld data-zoeken, code-schrijven of eindpresentaties maken. Ze verdelen taken onderling via een supervisor-agent of via een gedeelde geheugenbank. Het resultaat voelt soms als een klein team van junior-ontwikkelaars dat met elkaar chat om een opdracht af te ronden. Dit concept opent de deur naar complexere projecten, zoals een marketingcampagne die automatisch A/B-tests uitvoert en bijstuurt op basis van real-time statistieken.

Voorbeelden van AI Agents vs. AI pipelines
Nederlandse organisaties zien in de praktijk uiteenlopende casussen voorbij komen. De onderstaande voorbeelden helpen om het onderscheid tussen pipelines en agents scherp te houden. Verder laten ze zien hoe de keuze voor een bepaalde architectuur de efficiëntie en betrouwbaarheid beïnvloedt.- Automatische factuurverwerking bij een mkb-boekhoudpakket: de ontwikkelaars kozen voor een pipeline. Eerst haalt een cloud-functie e-mails op, dan volgt OCR. Het resultaat gaat door een veldextractiemodel en daarna naar het ERP-systeem. Elke stap is voorspelbaar. Facturen die sterk afwijken worden afgekeurd en handmatig nagekeken.
- Contentcuratie voor een online nieuwsplatform: hier draait een agent die trending onderwerpen opspoort, foto’s zoekt, koppen genereert en voorstellen doet aan de eindredactie. Hij pakt onderwerpen op die buiten de vaste rubrieken vallen, iets wat een pipeline niet zou signaleren.
- Predictief onderhoud bij een waterleidingbedrijf: sensoren sturen data naar een pipeline die afwijkingen detecteert. Als de pipeline een patroon ziet dat niet in het model past, roept een trigger een agent aan. Die agent voert aanvullende diagnostiek uit, zoals het opvragen van weersvoorspellingen en het controleren van historische incidenten, en adviseert vervolgens een monteur.
- E-commerce productbeschrijvingen: bij een groot retailbedrijf draait een pipeline die basisbeschrijvingen maakt. Daarnaast is er een creatie-agent actief voor promotie-campagnes. Komt er een seizoensactie, dan vraagt de agent nieuwe beelden aan bij een generatief model en herschrijft hij de tekst, inclusief emoji en kortingen.
- Juristen die contracten beoordelen: een pipeline haalt de belangrijkste clausules uit PDF’s. Een agent leest daarna de context, zoekt vergelijkbare uitspraken in jurisprudentie en maakt samenvattende notities. Hierdoor besparen advocaten tijd, terwijl ze toch de nuances van elk dossier kunnen beoordelen.
- Intelligente klokkenluiderslijn: om beter fraudemeldingen te analyseren, gebruikt een zorgverzekeraar een agent die e-mails categoriseert, sentiment meet en bewijsstukken verzamelt. De agent beslist zelf wanneer hij een zaak escaleren moet. Een pipeline zou alles naar dezelfde queue sturen, wat overbelasting oplevert bij het compliance-team.
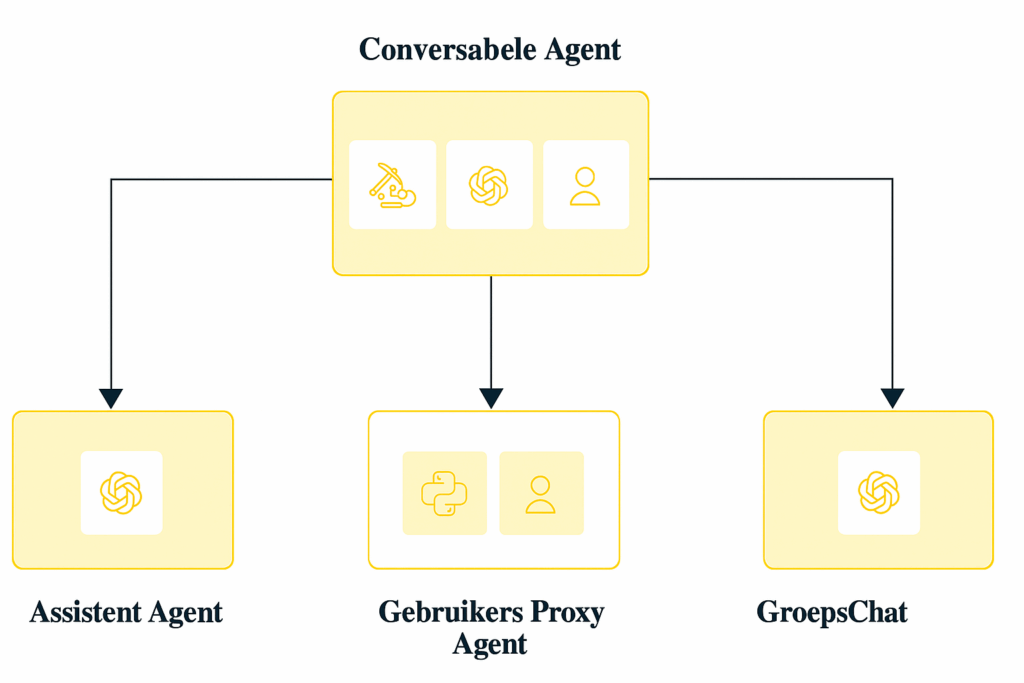
Afbeelding 3. Schematische afbeelding van samenwerkende AI agents in één omgeving.
Belangrijke overwegingen bij de keuze AI agent vs. pipeline
Wanneer je voor een nieuw project staat, helpt het om systematisch naar vijf domeinen te kijken. Op basis van die analyse kies je vervolgens voor een pipeline, een agent of een hybride vorm.
1. Variabiliteit van invoer en route: Hoeveel variatie verwacht je? Een pipeline gedijt op vaste structuren, terwijl een agent juist uitblinkt in verrassende situaties. Als de dataset sterk verandert of je doelen breed zijn, neem dan de agent in overweging.
2. Prestatie eisen: Heb je harde latency-grenzen, bijvoorbeeld in een realtime spel? Pipelines zijn lichter omdat ze geen uitgebreide plancyclus volgen. Agents kunnen wel caching toepassen, maar blijven gemiddeld trager.
3. Budget en schaal: Hoeveel budget is er beschikbaar? Agents verbruiken meer tokens en vragen meer CPU of GPU-cycles voor planningslogica. Als de kosten per request absoluut laag moeten blijven, kies dan een slanke pipeline en voeg desnoods een fallback-agent toe voor uitzonderingen.
4. Transparantie en audit: In gereguleerde sectoren wegen logbestanden zwaar. Pipelines loggen lineair, agents loggen boomstructuren. Dat is moeilijker uit te leggen aan auditors. Overweeg daarom extra visualisatietools als je agents inzet.
5. Onderhoud en teamvaardigheden: Vraag jezelf af welke vaardigheden er in het team aanwezig zijn. Is er ervaring met prompt-engineering en veiligheidsrails? Dan kun je een agent sneller beveiligen en onderhouden. Zo niet, begin dan met een pipeline om momentum op te bouwen.
Met duidelijke kaders voorkom je eenvoudig onaangename verrassingen in de latere projectfases.
Afbeelding 4. Amazon Bedrock Customer Service AI agent.
Hybride oplossingen: het beste van twee werelden
Niet elk project past netjes in het vakje pipeline of agent. Steeds vaker zien we teams die bewust kiezen voor een hybride architectuur waarin beide vormen samenwerken. Het idee is simpel: een slanke pipeline vangt de bulkverwerking af, terwijl een agent standby staat om afwijkende cases of meerstapsvragen op te lossen. Deze aanpak combineert de snelheid en voorspelbaarheid van een pipeline met de flexibiliteit van een agent. Daardoor vermijd je de hoge kosten van een agent die onbeperkt draait, maar behoud je wel de mogelijkheid om complexe situaties op te pakken.
Een goed voorbeeld is een klantenserviceplatform dat chatberichten verwerkt. De pipeline classificeert binnenkomende teksten, detecteert taal en controleert of er verboden woorden in staan. In negentig procent van de gevallen volstaat een standaardantwoord of een handmatig samengestelde FAQ-paragraaf. Voor de resterende tien procent roept het systeem een agent aan die vervolgvraagstukken oplost, aanvullende data zoekt en zelfs een concept-mail opstelt voor een menselijke medewerker. De klant krijgt daardoor sneller een passend antwoord, terwijl de organisatie grip houdt op de kosten.
Een ander scenario komt uit de zorg. Een ziekenhuis gebruikt een pipeline om röntgenbeelden door een geaccrediteerd model te halen. Zodra de uitslag afwijkend is, schakelt het systeem een radiologie-agent in. Die agent haalt aanvullende patiëntgegevens op, vergelijkt eerdere scans en levert een voorlopige diagnose. De combinatie zorgt voor snellere doorlooptijden zonder kwaliteit in te leveren.
Uitdagingen en valkuilen bij agents
Hoewel agents veelbelovend zijn, is het verstandig om mogelijke struikelblokken niet te onderschatten. Voorkom verrassingen door de onderstaande uitdagingen al in de architectuurfase mee te nemen.
- Run-away gedrag: Een e-commerce-agent bleef herhaaldelijk de productdatabase pingen omdat hij ontevreden was over de gevonden resultaten. Zonder taaklimiet liep de rekening hard op.
- Gebrekkige traceerbaarheid: Sommige agent-runs bevatten honderden gedetailleerde chain-of-thought aanwijzingen. Het opslaan en terugzoeken daarvan vereist gespecialiseerde tooling, zoals vector-databases en dashboards met zoekfilters.
- Complexe foutafhandeling: Als een agent meerdere routes parallel probeert, kan een enkele fout hem uit balans brengen. Ontwikkelaars moeten fallback-strategieën ontwerpen, bijvoorbeeld door snel terug te vallen op een simpeler pipelinepad.
- Tokenbudgetten onder druk: Een actuarieel bureau zag de kosten voor LLM-calls verdubbelen toen een agent extra contextvakken meenam. Uiteindelijk verbeterden zij de prompts, maar alleen na een grondige review.
- Afhankelijkheid van toolkwaliteit: Als een onderliggende API verandert, krijgt de agent onverwachte foutcodes. Zonder proactieve monitoring gaat hij door op een verkeerd pad en levert hij slechtere output.

Aanbevelingen voor implementatie
Hieronder vind je een reeks aanbevelingen die voortkomen uit interviews en open-sourceprojecten. Ze helpen je om valkuilen te vermijden en sneller waarde te leveren.
- Begin klein en meet alles: Of je nu een pipeline of agent inzet, start met een afgebakende use-case. Meet latency, kosten en foutpercentages. Schaal pas op wanneer je duidelijk ziet dat de gekozen opzet werkt.
- Implementeer defensive programming: Voeg guardrails toe tegen onverwachte invoer. In een pipeline betekent dit schema-validatie; bij agents woordenfilters, timeout-mechanismen en max-tokens-limieten.
- Zorg voor explainability: Houd per stap bij hoe het model tot zijn output kwam. Voor pipelines log je scores en tussenresultaten. Voor agents sla je beslis-trees op met context-snapshots.
- Integreer Human-in-the-loop principe: Laat bij twijfelgevallen een medewerker meekijken. Een eenvoudige goed-keurknop in de interface voorkomt dat een agent ongewenste acties uitvoert.
- Automatiseer regressietests: Bouw een testset met representatieve input. Draai die dagelijks. Zo zie je direct of de prestaties achteruit gaan wanneer je een nieuw model toevoegt.
- Kies een passende observability-stack: Tools als OpenTelemetry en Prometheus werken prima met pipelines. Voor agents heb je daarnaast conversation-logging en misschien een vector-database nodig voor geheugeninspectie.
- Plan onderhoudscycli: Modellen verouderen. Leg vast wanneer je data moet verversen of prompts moet updaten. Zo voorkom je prestatieverlies.
- Blijf bij standaarden: Gebruik open protocollen voor tool-interfaces. Hierdoor kun je later makkelijk wisselen tussen modellen of cloudproviders zonder een volledige rewrite.
- Train het team: Richt interne workshops in over prompt-engineering, monitoring en ethiek. Goed getrainde medewerkers herkennen problemen sneller en lossen ze adequaat op.