Wat Artificiële Intelligentie (NLP) kan met tekst
28 juli, 2020

Rick Vink – Expert in Machine Learning & Deep Learning
“Natural Language Processing (NLP) is een snel ontwikkelend veld. Tegenwoordig zien we iedere paar maanden een nieuw opwindend resultaat dat gepubliceerd wordt met nieuwe methoden die nóg beter in staat zijn kennis te halen uit tekst. “
Tekst, een gigantische onontgonnen bron van informatie. Artificiële Intelligentie (AI) kan met behulp van Natural Language Processing (NLP) ons helpen deze bron beter te benutten. Daarvoor is het nodig dat AI dit weet te interpreteren, zodat wij daarop kunnen handelen. Enkele voorbeelden van toepassingen: vragen stellen aan de hand van een tekst, een vraag doorverwijzen naar de juiste persoon binnen een organisatie of de behoeftes van klanten beter leren begrijpen. Maar kan een AI dat al? En hoe kan dat? In deze blog lees je meer over de dingen die al kunnen met NLP.

Afbeelding 1: Test resultaten van het voorspellen of een review positief is of negatief. Deze testset bestaat uit 600 review waarvan 50% positief is en 50% negatief. X-as is de Epoch: hoe vaak het de data heeft gezien. Waarbij epoch 1 één keer de data heeft gezien en epoch 10 tien keer de data heeft gezien. Y-as is de accuractie: hoeveel van de data heeft het goed voorspeld. Waarbij dus de modellen tussen de 75% en 90% als score hebben.
Het kiezen van het juiste model is belangrijk. Vaak loont het om een pretrained model te gebruiken zoals BERT (een getraind model van Google). Dit model heeft dagenlang wikipedia en andere teksten ‘gelezen’ om zo taal te ‘begrijpen’. Daarna is het leren van jouw specifieke opdracht met een paar voorbeelden al goed te doen.
Naast een goed model speelt de kwaliteit en kwantiteit van je data een zeer grote rol. Een vers model heeft met een paar samples niet genoeg ervaring om goed onderscheid te kunnen maken tussen positieve en negatieve reviews. Gelukkig kan een pre-trained model een hoop goed maken, omdat het al kennis heeft van de taal. Hierdoor hoeft het enkel nog te leren wat je precies wilt met de tekst.
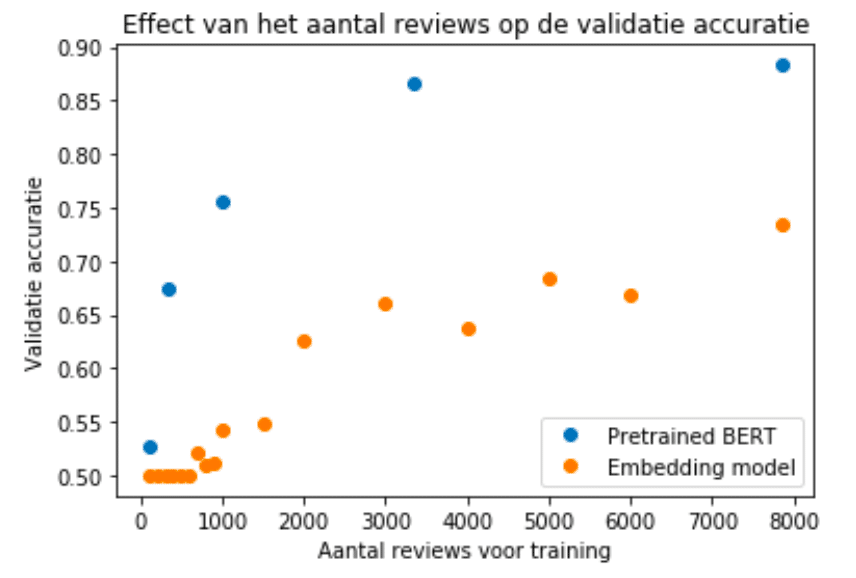
Afbeelding 2: Het effect van trainen van een model met een beperkte hoeveelheid data. Hier zie je dat een nieuw model dat nooit op tekst is getraind bijna 1000 voorbeelden nodig heeft voordat het een beetje van de grond komt. Daarentegen heeft het pretrained BERT model al een vliegende start. Elk datapunt is een uniek getraind model. X-as: Het aantal samples dat gebruikt is tijdens het trainen. Y-as: De prestatie van het model.
Natural Language Processing is een snel ontwikkelend veld. Tegenwoordig zien we iedere paar maanden een nieuw opwindend resultaat dat gepubliceerd wordt met nieuwe methoden die nóg beter in staat zijn kennis te halen uit tekst. Op dit moment schijnt de trend te zijn: meer data en groter model voor een beter resultaat. Deze modellen kosten veel tijd en geld om te trainen. Gelukkig worden de meeste modellen publiekelijk vrijgegeven, zodat iedereen die de juiste kennis heeft ze kan gebruiken voor hun zijn of haar uitdagingen.
Wil jij zelf NLP technieken leren begrijpen en toepassen?
“Deze 1-daagse cursus is ideaal om wegwijs te geraken met NLP.”
Vincent Janssen – AI/System Engineer bij Verhaert