Wat is Natural Language Processing (NLP)?
Update: 28 juni, 2023

Rick Vink – Expert in Machine Learning & Deep Learning
“Natural Language Processing (NLP) is het vakgebied binnen Kunstmatige Intelligentie (AI) dat zich bezighoudt met het analyseren van menselijke taal en de communicatie tussen mens en computer. Dit zijn vaak complexe vraagstukken waar een combinatie van meerdere Natural Language Processing technieken voor nodig zijn.“
De introductie van ChatGPT heeft een groot deel van de Nederlandse bevolking in contact gebracht met geavanceerde taalmodellen. Maar wat zijn ze precies? Hoe functioneren ze? En welke alternatieven zijn er voor ChatGPT?
Er zijn tekstgeneratoren in verschillende soorten en maten. Hoewel tekstgeneratoren momenteel het meest bekend zijn, bestaan er ook modellen die op een andere manier werken, zoals tekstclassificatiemodellen en tekstclusteringmodellen.

Afbeelding 1. De evolutie van moderne taal modellen. Deze visualisatie is van Harness the power of LLMs in Practice
Inhoudsopgave
Wat is Natural Language Processing?
De betekenis van Natural Language Processing (NLP) is het analyseren en/of genereren van, natuurlijke, taal met computer technieken. Er bestaan eenvoudige NLP-technieken, zoals bijvoorbeeld het tellen van woorden om bepaalde conclusies te trekken. Aan de andere kant van het spectrum bevinden zich complexere NLP-methoden zoals ChatGPT. Hierbij wordt een Deep Learning netwerk gebruikt om text te analyseren. Deze geavanceerdere benaderingen stellen ons in staat om complexe taalkundige patronen en structuren te herkennen en te genereren.
Toepassingen van Natural Language Processing
Teksten genereren
Als je aan Tekst genereren denk dan denk je aan ChatGPT. Dit komt omdat dit model als eerste met een uitgebreidere gebruiksvriendelijke interface werd uitgebracht. Deze modellen voorspellen de kans van mogelijke volgende woorden op basis van de vorige tekst. Dit is de reden waarom je bij ChatGPT het antwoord woord voor woord ziet verschijnen.
ChatGPT is versie 3.5 van de ChatGPT modellen. Dit betektend dus dat er meerdere versie zijn geweest voot ChatGPT. We hebben in 2019 het GPT-2 model toegepast bij het maken van kookrecepten. Hiervoor trainden wij het GPT-2 model om automatisch kookrecepten te genereren. Wat bleek? De recepten waren goed eetbaar wanneer ze klaargemaakt werden! Oftewel, AI is in staat middels GPT-2 kookrecepten te bedenken.
Berichten filteren
We zijn allemaal wel bekend met de spamfolder in ons e-mail systeem. Dit systeem bespaart ons veel tijd wanneer we onze mailbox doorspitten. Deze mails worden herkend op het woordgebruik en de schrijfstijl met behulp van een kunstmatige intelligentie.
Hiernaast zijn er vele andere situaties waar het filteren van berichten heel handig is. Denk bijvoorbeeld aan de klantenservice waar veel berichten van klanten binnenkomen. Al deze berichten moeten uiteindelijk naar de juiste persoon worden geleid. Dit wordt in sommige gevallen nog met de hand gedaan. Gelukkig is dit een proces dat goed te automatiseren is met behulp van Natural Language Processing. Kunstmatige Intelligentie kan woorden en/of woordcombinaties leren herkennen die belangrijk zijn voor het classificeren van de content. Vervolgens kan deze naar de juiste persoon worden doorgestuurd. Zo kan er een hoop tijd worden bespaard!
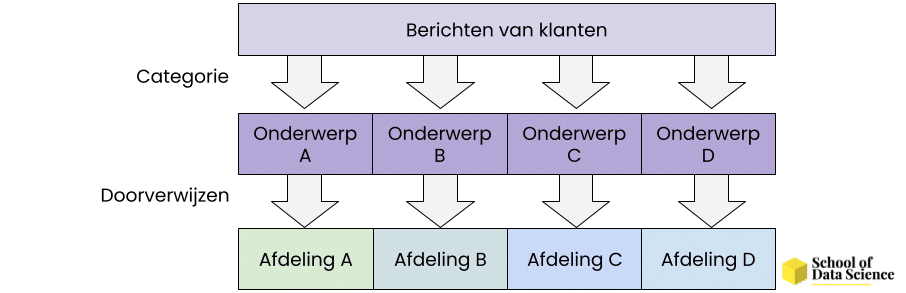
Afbeelding 2. NLP kan organisaties helpen bij het automatisch stroomlijnen van communicatie vanuit klanten. Op deze manier komt iedere klant direct bij de juiste afdeling terecht.
Sentiment analyse
Sentiment analyse is bedoeld voor het achterhalen van emotie uit teksten. Zo zijn er bijvoorbeeld veel opinies te vinden op social media. Denk aan: Wat vindt men van de prijs van ons product? Hoe vindt men de kwaliteit? Zijn de klanten blij met de service? Het bijhouden van hoe het publiek denkt over je product is heel waardevol. Deze informatie kan bijvoorbeeld dienen als sturing voor het verbeteren van het product of het stroomlijnen van je bedrijfsprocessen.
Naast social media kan sentiment analyse ook worden toegepast op e-mails van klanten, antwoorden van open vragen in enquêtes en gesprekken van klanten met de klantenservice. Dit maakt sentiment analyse een zeer krachtige tool om in kaart te brengen wat goed gaat met een product en ook waar nog verbeterd kan worden.

Afbeelding 3. NLP kan voor verschillende producten bijhouden wat het publieke sentiment is. Met behulp van deze informatie kunnen producten en diensten verbeterd worden.
Teksten doorzoeken en vragen met antwoorden vinden
Organisaties beschikken over veel informatie. Hier zit veel waarde in voor bijvoorbeeld het beantwoorden van vragen die intern of extern gesteld worden. Echter is deze informatie vaak minder toegankelijk omdat het om veel data gaat. Vaak staat die data niet in een handige vorm om gemakkelijk doorzocht te worden. Dit kan gaan om data in verschillende bestandstypen of gesloten systemen. Kortom: zoeken naar een naald in een hooiberg dus.
Een tak van sport binnen Natural Language Processing is het bepalen in hoeverre de inhoud van teksten op elkaar lijken. Zo kan een nieuwe vraag worden vergeleken met vragen die eerder gesteld zijn, waarbij je de bijbehorende antwoorden tevoorschijn kan halen. Een voorbeeld hiervan kan je vinden op Tweedekamervrager. Hier hebben we een portaal gemaakt die vergelijkbare vragen vindt in de database van de Tweede Kamer.
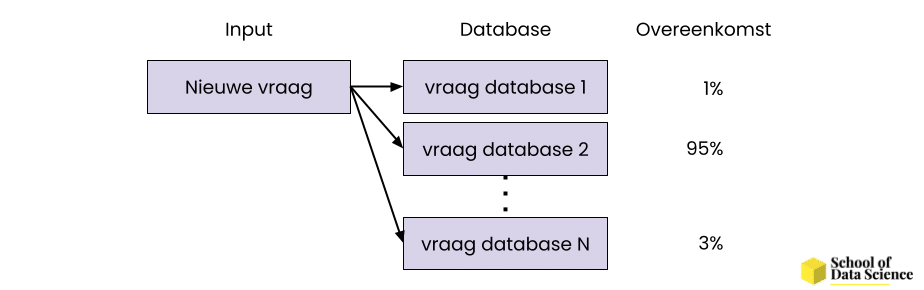
Afbeelding 4. NLP kan gebruikt worden om antwoorden te voorzien op vragen of zoekopdrachten. Op deze manier vinden gebruikers de meest relevante content bij hun zoekopdracht.
Wilt u Natural Language Processing gebruiken in uw werkzaamheden?
De Geschiedenis van Natural Language Processing in het Kort
De ontwikkeling van AI-taalmodellen bestaat al enkele decennia. Een significante stap in de moderne wereld werd gezet met de introductie van het LSTM-model. Dit is een deep learning model dat in 2016 de basis vormde voor Google Translate en het ELMo-model in 2017. Kort daarna introduceerde Google het transformer-model, dat de basis vormt voor modellen zoals ChatGPT, BERT, GPT-4, BART, LLama en vele andere.
Hoe werkt Natural Language Processing?
Verschillende taaluitdagingen zijn opgelost met technieken uit de NLP-wereld – een indrukwekkende prestatie! Hoewel de modellen zelf voor beginners complex kunnen lijken, zijn de basisconcepten vrij toegankelijk. De NLP-concepten die we in dit stuk zullen behandelen, zijn in de meeste NLP-toepassingen geïmplementeerd. Het begrijpen van deze concepten zal niet alleen je waardering voor Natural Language Processing vergroten, maar ook je inzicht in hoe het werkt.
Klassieke Natural Language Processing technieken
Een methode die goed werkt om tekst te analyseren is door simpelweg het aantal woorden te tellen. Deze methode noemen we bag of words. Hiermee kunnen al enkele basale conclusies getrokken worden. Het is met name zo dat een tekst met voornamelijk positieve woorden, zoals “goed”, “geweldig” of “blij” waarschijnlijk positief is. In tegenstelling tot teksten die vooral negatieve woorden bevatten.
Hiervoor wordt meestal de tekst gefilterd door minder belangrijke woorden zoals “en”, “de”, “het” weg te halen. Dit omdat die weinig waarde geven aan een tekst. Daarnaast helpt het om woorden te versimpelen. Denk bijvoorbeeld aan de woorden “zwemmen” en “gezwommen” naar “zwem”. Dit process verliest voor vele toepassingen geen belangrijke informatie. Dit versimpelen noemen we lemmatiseren.
Deze manier van analyseren verliest echter veel informatie. Die informatie kan belangrijk zijn wanneer je te maken hebt met complexere NLP toepassingen. De voornaamste informatie die verloren gaat is de volgorde van de woorden. Vergelijk bijvoorbeeld de volgende zinnen: “Ik ben niet boos, maar juist blij.” met “Ik ben niet blij maar juist boos”. Je kunt zien dat dezelfde woorden voorkomen. Echter hebben de zinnen een totaal andere betekenis.
Moderne Natural Language Processing technieken
De meeste NLP-algoritmes vertalen woorden of delen van woorden, ook wel ‘tokens’ genoemd, naar reeksen van getallen. Deze reeksen worden vectoren genoemd en drukken de betekenis van elk woord uit. zie afbeelding 5.
Deze vectoren hebben de bijzondere eigenschap dat de getallen voor woorden met vergelijkbare betekenissen dicht bij elkaar liggen. Zo zullen de vectoren voor “Amsterdam” en “Den Haag” dicht bij elkaar liggen, omdat beide termen naar steden verwijzen. Daarentegen zullen de vectoren voor “Amsterdam” en “Appeltaart” verder uit elkaar liggen, gezien deze woorden totaal verschillende betekenissen hebben.
Vervolgens worden deze vectoren verwerkt door taalmodellen, zoals ChatGPT. ChatGPT maakt bijvoorbeeld een voorspelling van het volgende woord in een zin, gebaseerd op de context van de voorafgaande woorden. Hierbij worden de vectoren gebruikt om zinvolle en coherente voorspellingen te genereren.
Je vraagt je nu waarschijnlijk af wat deze taalmodellen precies zijn? Deze modellen zijn gebaseerd op Deep Learning technieken, een onderwerp dat we in het volgende hoofdstuk uitgebreid zullen behandelen!

Afbeelding 5. Moderne Natural Language Processing technieken maken gebruik van vectoren om woorden of woorddelen te beschrijven. Deze vectoren gaan vervolgens een Deep Learning model in.
Wil jij zelf NLP technieken leren begrijpen en toepassen?
“Deze 1-daagse cursus is ideaal om wegwijs te geraken met NLP.”
Vincent Janssen – AI/System Engineer bij Verhaert
Natural Language Processing met Deep Learning
Deep Learning heeft de afgelopen jaren veel succes geboekt. Technologieën als Google Translate werken zo goed dankzij de komst van Artificial Neural Networks wat een essentieel onderdeel is van Deep Learning. Op dit moment lijkt er nog geen limiet bereikt te zijn met de huidige Deep Learning technieken als het gaat om hoe goed NLP modellen kunnen presteren. De eerdere trend leek “hoe groter het model, hoe beter het resultaat”, maar tegenwoordig ligt de focus voornamelijk op de kwaliteit van de data en de methode van training om verdere verbeteringen te realiseren.
Er zijn twee specifieke Deep Learning-modellen die aanzienlijk hebben bijgedragen aan de ontwikkeling van Natural Language Processing. Enerzijds hebben we het Recurrent Neural Network (RNN), dat in het verleden een aanzienlijke rol heeft gespeeld. Anderzijds zien we tegenwoordig dat de hoogst presterende modellen, zoals BARD, ChatGPT en BERT, zijn gebaseerd op de Transformer-architectuur.
Recurrent Neural Network (RNN)
Recurrent Neural Networks hebben veel los gemaakt met wat mogelijk is met Deep learning. RNN modellen zoals LSTM en GRU zijn modellen waarbij waardes één voor één worden verwerkt. In Natural Language Processing worden deze modellen toegepast door een zin woord voor woord te verwerken. Nadat elke vector door de RNN verwerkt is eindig je met een samenvatting van de zin. Deze samenvattende vector wordt vervolgens weer verder verwerkt door een standaard neuraal netwerk (Feed Forward network) om tot de uiteindelijke conclusie te komen.

Afbeelding 6. Recurrent verwerken stukjes van de data een voor een. Dit kunnen bijvoorbeeld woorden zijn die een voor een door het model worden verwerkt.
Transformers
De transformer is op dit moment het meest geavanceerde model. Deze Deep Learning architectuur maakt gebruik van attentie lagen waarbij het gaat om verbanden leggen tussen woorden. Grotere modellen zoals het BERT model van Google en ChatGPT / GPT van OpenAI hebben maar liefst 13 en 96 lagen van attentie met een Feed Forward reken stap.

Afbeelding 7. Transforms zijn de beste modellen voor Taal analyse op dit moment. De meest geadvenceerde modellen zoals BERT en GPT gebruiken een transformer als kern van het model.
Het proces van een NLP model trainen
Het trainen van een goed NLP model is niet recht toe recht aan; het is namelijk een hele opgave om taal goed te begrijpen. Als je een ongetraind model direct inzet op het leren van een specifiek probleem, zal het resultaat teleurstellend zijn. Dit komt omdat het model de taal nog niet begrijpt en zal grijpen naar simpele patronen waar zo goed als geen taal kennis voor nodig is.
Het is daarom extra belangrijk om voort te bouwen op een model dat de taal eigen heeft gemaakt. Dit principe heet fine-tuning en zal naast een beter resultaat ook een stuk sneller trainen. Deze modellen zijn weken lang getraind op een super computer waarbij ze vraagstukken moeten oplossen zoals missende woorden invullen in een tekst.
Hiervoor is veel train data nodig. Het liefst train je een model waarbij de labels bekend zijn. Deze manier van leren heet supervised learning. Echter moet je daarvoor veel gelabelde data hebben wat duur is om te maken. Daarentegen heeft unsupervised learning geen labels nodig om te trainen; waardoor het veel goedkoper is. Het nadeel van unsupervised learning is weer dat het niet altijd leert wat jij wilt dat het leert.
Gelukkig is voor dit probleem een tussenoplossing: self-supervised learning. Hierbij worden bestaande teksten van het internet afgehaald en woorden achteraf weggehaald en opgeslagen als labels. Zo kan je heel goedkoop een gelabelde dataset maken.
Software voor NLP
Natural Language Processing met Python
Python is de programmeertaal die je moet gebruiken als je de laatste en meest geavanceerde NLP modellen wilt toepassen. Python heeft een rijke geschiedenis op het gebied van data science. Python is de afgelopen jaren in populariteit gestegen. Er is meer vraag naar data wetenschappers die Python beheren dan data wetenschappers die R beheren.
Natuurlijk is niet iedereen direct klaar om Natural Language Processing met Python te leren. Het is en blijft een programmeertaal waarvoor de nodige ervaring vereist is. Gelukkig is Python een relatief eenvoudige programmeertaal om te leren. Afhankelijk van hoe snel je nieuwe dingen oppikt kan je al binnen een half jaar prima met NLP gaan werken in Python. Hiervoor is aan te raden om eerst de basis van Python te leren, gevolgd met data science in Python of Machine Learning in Python en daarna een begin te maken in Deep Learning.
Natural Language Processing met Tools in Python
Er bestaan zowel opensource als closed-source modellen voor NLP. De opensource modellen zijn gemakkelijk te vinden op platforms zoals Hugging Face, of je kunt ze direct van de betreffende GitHub-pagina’s downloaden. Daarentegen zijn er ook talrijke closed-source modellen beschikbaar, waaronder het ChatGPT-model of BARD. Deze modellen kunnen worden gebruikt via een online interface of via een API.
Er zijn twee Deep Learning frameworks die op dit moment worden gebruikt voor Natural Language Processing: TensorFlow (ontwikkeld door Google) en PyTorch (ontwikkeld door Facebook). Beide Frameworks zijn een goede keuze. Waarbij TensorFlow komt van de filosofie dat code optimaal moet kunnen werken in productie en PyTorch dat de code intuïtief moet zijn. Beide frameworks zijn nu vrij vergelijkbaar qua gebruik. Bij School of Data Science gebruiken we zelf TensorFlow als standaard framework.
Hoe kan School of Data Science jou helpen met Natural Language processing?
We hebben geleerd dat Natural Language Processing vele toepassingen heeft. Daarna hebben we gezien dat er vele stappen komen kijken wanneer we NLP toepassen. Er zijn nog vele onaangetaste toepassingen van NLP waar jij misschien wel mee te maken hebt.
Natural Language Processing zal alleen maar beter en belangrijker worden. Het is daarom zeer waardevol om jezelf te verdiepen in de wereld van NLP. Wij van School of Data Science helpen graag mee denken met jouw ontwikkeling op het gebied van NLP. Dit kan zijn door jou NLP te leren met een van onze cursussen of door jouw te helpen bij het toepassen van NLP op jouw uitdagingen. Neem contact met ons op of bekijk onze pagina voor NLP consultancy.
Wil jij zelf NLP technieken leren begrijpen en toepassen?
“Deze 1-daagse cursus is ideaal om wegwijs te geraken met NLP.”
Vincent Janssen – AI/System Engineer bij Verhaert